

Wat is een Datawarehouse?
Alles te weten komen over BI & Analytics?
Cadran-analytics.nl is hier dé plek voor. Ontdek de mogelijkheden van Business Intelligence & Analytics tools om waardevolle inzichten te krijgen in uw data.
Oracle BI – Overpeinzingen (6) – Cadran publiceert een reeks artikelen over het gedachtegoed rondom Oracle Business Intelligence in combinatie met Oracle JD Edwards. In deze artikelen komen diverse overwegingen en overpeinzingen aan bod, die behulpzaam kunnen zijn in het maken van de juiste beslissingen bij de implementatie en toepassing van beide systemen. In de voorgaande artikelen is ingegaan op het sterschema, feiten, dimensies en het samenspel tussen deze twee. In dit artikel wordt ingegaan op de betekenis en rol van zogenoemde datawarehouses.
Wat is een datawarehouse?
Een datawarehouse is uiteindelijk ‘ook gewoon maar‘ een database met tabellen en velden en daarin records met data. Oracle BI kan elke databron ontsluiten en dus ook de datawarehouse-database.
Waar een datawarehouse echter direct voor bedoeld is, is om grote hoeveelheden data uit (mogelijk meerdere) bronsystemen op een slimme manier klaar te zetten om op een efficiënte en dus snelle manier antwoord te kunnen geven op de voor de hand liggende vragen. Dit gebeurt in zogenoemde kubussen, die de benodigde aggregaties op allerlei niveaus bijhouden. Daarnaast is een datawarehouse in staat verloop van data door de tijd heen vast te leggen, zodat historisch verloop mogelijk wordt gemaakt. In de theorie van Ralph Kimball komt dit al naar voren onder de noemer Slowly Changing Dimensions.
Een voorbeeld van dit laatste begrip is een nieuwe vertegenwoordiger, die in dienst komt en de werkzaamheden overneemt van iemand die met pensioen gaat. Wanneer deze vertegenwoordiger gekoppeld wordt aan diens klanten, dan zou deze man direct bij binnenkomst voor een aardige omzet hebben gezorgd. Om dit beeld zuiver te houden, is inzicht in het aspect tijd dat hierbij speelt nodig, maar ook een medewerkersstatus (zoals Uit Dienst).
Een ander voorbeeld is de standaard Accounts Receivable informatie. Indien met Oracle BI de informatie van Openstaande Facturen en Openstaande Dagen inzichtelijk worden gemaakt, praten we bij Oracle JD Edwards altijd over de situatie van dit moment. Hoeveel facturen staan er open? Hoe hoog zijn de openstaande bedragen? Welke klanten hebben te grote betalingsachterstanden? Maar als deze stand met vorig jaar moet kunnen worden vergeleken om te analyseren welke klanten zich beter of juist slechter gaan gedragen, dan zal de data in Oracle JD Edwards deze informatie niet (zomaar) kunnen ophoesten.
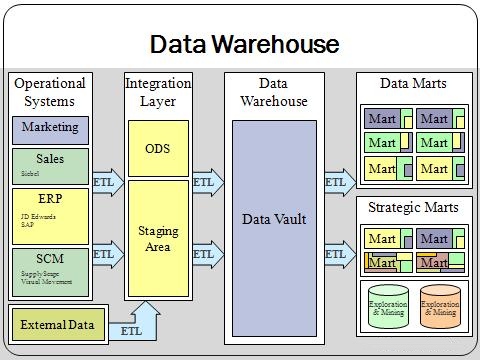 Een datawarehouse is in staat bovenstaande aspecten te kunnen bedienen. Daarnaast geeft een datawarehouse de mogelijkheid informatie die over allerlei bronnen en systemen in de organisatie is verspreid centraal te combineren. Hierdoor is het zelfs mogelijk allerlei verouderde datastructuren, Excel-sheets en tekstbestanden te integreren in een centraal te ontsluiten database. Daarnaast stelt het een Oracle BI-oplossing in staat eenvoudig over deze centrale opslag te rapporteren. Zou verkooporderhistorie uit Oracle JD Edwards eenvoudig gecombineerd en vergeleken kunnen worden met een CRM-systeem om bijvoorbeeld ordersucces en offerteduur te bepalen.
Een datawarehouse is in staat bovenstaande aspecten te kunnen bedienen. Daarnaast geeft een datawarehouse de mogelijkheid informatie die over allerlei bronnen en systemen in de organisatie is verspreid centraal te combineren. Hierdoor is het zelfs mogelijk allerlei verouderde datastructuren, Excel-sheets en tekstbestanden te integreren in een centraal te ontsluiten database. Daarnaast stelt het een Oracle BI-oplossing in staat eenvoudig over deze centrale opslag te rapporteren. Zou verkooporderhistorie uit Oracle JD Edwards eenvoudig gecombineerd en vergeleken kunnen worden met een CRM-systeem om bijvoorbeeld ordersucces en offerteduur te bepalen.
Uiteraard komt bij het opzetten van een datawarehouse direct weer definitie om de hoek kijken ten einde vergelijking tussen appels en peren te voorkomen. Daarnaast zal het datawarehouse de bron van informatiebehoefte moeten gaan dekken. Naar het bovenstaande voorbeeld vertaalt, zal bekend moeten zijn wat tot verkooporderhistorie kan worden gerekend (welke selectiecriteria, zoals ordertypes, regeltypes, orderstatussen en tegen welke datum). Vervolgens zal consensus moeten gaan ontstaan over het begrip klant indien meetwaardes als ordersucces en offerteduur per klant of klantgroep moeten kunnen worden weergegeven. Een klant in Oracle JD Edwards is immers mogelijk een andere begrip dan in een CRM-systeem.
Zie Wikipedia voor meer informatie.
Transactionele database vs. Datawarehouse database
Wanneer op een machine een Oracle Database wordt geïnstalleerd, is dit zo beetje de eerste vraag die in het installatieproces wordt gesteld. Is de te installeren database bedoeld voor transacties of als datawarehouse? Ofschoon het aanvankelijk niet zo uit lijkt te maken, wordt er toch een aantal essentiële parameters in de database anders ingesteld. Uiteindelijk wordt data uit een database middels SQL bevraagd. Oracle BI is hier niet anders in. Wel is het allemaal te doen om de optimale executieplannen van deze SQL-statements, waardoor een hoge performance kan worden behaald. Hoe krijg je heel veel data in een korte tijd op het scherm. Alle systemen en technieken zijn er dus opgericht een zo hoog mogelijke optimalisatie van deze SQL-statements te realiseren. Deze optimalisatie ziet er voor een transactionele database uiteraard essentieel anders uit dan voor een datawarehouse. Het opslaan van een verkooporder met tien orderregels is immers wat anders dan het bevragen van de totale omzet per maand versus die van vorig jaar.
JDE – DWH – OBI
Proberen we dit alles te verplaatsen naar de wereld van Oracle JD Edwards en Oracle BI dan vereist deze combinatie in eerste instantie niet persé een datawarehouse. Zeker als de hoeveelheid data te overzien is, is het technisch prima mogelijk om met Oracle BI rechtstreeks de database van Oracle JD Edwards te bevragen. De BI Server waarin het logisch informatiemodel opereert gaat dan eigenlijk als een datawarehouse in geheugen fungeren.
 Veel gebruikers van Oracle JD Edwards hebben dan ook niet de omvang, waardoor een datawarehouse een vereiste is. Toch verdient het aanbeveling wel serieus na te denken over deze materie alvorens een Oracle BI-implementatie wordt gestart. De belangrijkste afwegingen, die hierbij spelen zijn:
Veel gebruikers van Oracle JD Edwards hebben dan ook niet de omvang, waardoor een datawarehouse een vereiste is. Toch verdient het aanbeveling wel serieus na te denken over deze materie alvorens een Oracle BI-implementatie wordt gestart. De belangrijkste afwegingen, die hierbij spelen zijn:
- Hoe kunnen (complexe en/of zware) SQL’s op het operationele Oracle JD Edwards systeem worden voorkomen of is dat niet erg?
- Wat voor eisen gelden voor historische data en data door de tijd heen (Slowly Changing Dimensions)?
- Wat voor eisen gelden voor performance? (Dit is immers mede een gevoelskwestie)
- Wat voor combinatie van data uit andere systemen dan alleen Oracle JD Edwards zijn in de Oracle BI-oplossing nodig?
- Wat voor eisen stel ik aan de actualiteit van data? (mogelijk combinatie van datawarehouse en zogenoemde Real Time informatie)
Maar met een datawarehouse komt er een extra verdieping in het ICT-landschap bij met de bijbehorende zorgen, beheer, kosten en onderhoud. Niet elke organisatie zit daar direct op te wachten of heeft de IT-organisatie om dit er ‘even’ bij te nemen. Er zijn echter alternatieven die in zwaarte variëren. Dit kan in de vorm van Staging Areas, data-replicatie of nog eenvoudiger Materialized Views in de database van Oracle JD Edwards. Op die manier kan er tot een soort DataWareHouse Light worden gekomen.
Met het juiste Oracle BI Informatie Model is het echter eenvoudig ook in een later stadium een datawarehouse op te zetten en als gegevensbron met Oracle BI te ontsluiten. Zolang de definities niet wijzigen, is er immers ‘slechts’ sprake van een andere gegevensbron, maar blijft Klant en Omzet ‘simpelweg hetzelfde’. Dit is uiteraard sterk gechargeerd, maar de boodschap klopt in essentie.
Oracle BI Applications
 Met Oracle BI Applications worden kant en klare dashboards, analytics en data-ontsluiting aangeboden. Deze zijn tot stand gekomen uit talloze implementaties en jarenlange ervaringen. Oracle BI Applications kan gezien worden als een best of breed standaard oplossing. Voor Oracle JD Edwards is dit beschikbaar voor de onderwerpsgebieden Finance en voor Sales Order Management. Op de rol staan Procurement en Manufacturing. Daar hoort een kant en klaar Datawarehouse bij. Het is dan ‘alleen’ nog maar zaak de ETL (Extract Transform & Load), die het datawarehouse voedt, aan Oracle JD Edwards te configureren (de JD Edwards Adapter). Niet direct ontsloten modules zijn bij te bouwen.
Met Oracle BI Applications worden kant en klare dashboards, analytics en data-ontsluiting aangeboden. Deze zijn tot stand gekomen uit talloze implementaties en jarenlange ervaringen. Oracle BI Applications kan gezien worden als een best of breed standaard oplossing. Voor Oracle JD Edwards is dit beschikbaar voor de onderwerpsgebieden Finance en voor Sales Order Management. Op de rol staan Procurement en Manufacturing. Daar hoort een kant en klaar Datawarehouse bij. Het is dan ‘alleen’ nog maar zaak de ETL (Extract Transform & Load), die het datawarehouse voedt, aan Oracle JD Edwards te configureren (de JD Edwards Adapter). Niet direct ontsloten modules zijn bij te bouwen.
Alle verhandelingen in dit artikel zijn daarmee in één klap beantwoord. Wel dient zich opnieuw het vraagstuk van definitie aan. Wat krijgen we dan eigenlijk te zien? Het verdient de grootste aanbeveling hier uitsluitend bij een reeds in gebruik zijnde Oracle JD Edwards implementatie hierover na te denken. Pas als de ‘stekker’ in een goed gevulde JD Edwards-database wordt gestoken, komen de dashboards tot leven en is deze standaardoplossing met een fit/gap-analyse te toetsen tegen de informatiebehoefte van de organisatie.
In vorige artikelen is ingegaan op de aspecten die bij dimensioneel modelleren komen kijken. Het al dan niet inzetten van een datawarehouse is hierin een keuze, maar geen noodzaak. Alles heeft te maken met de omvang en de volwassenheid van de oplossing en de organisatie. In de komende artikelen worden precies deze aspecten bekeken.
Meer informatie?

Auteur: Rick Brobbel
BI Consultant bij Cadran Consultancy

